Database design for Google Calendar: pt. 7
Previously in the seriesThis is the final post in the “Modeling Google Calendar” series. Previously:
This series illustrates the database design approach explained in the book called “Database Design using Minimal Modeling”, scheduled to be released in Summer 2024. Here is the website of the book: https://databasedesignbook.com/. You can subscribe to receive updates on the book and to get notified about new database design content. In the final chapter we’re going to design physical tables, based on the logical model defined in the previous chapters. Part 7. Creating SQL tablesIn the previous chapters we defined the complete logical model, so most of the work is actually already done. The rest is pretty straightforward. For teaching purposes we’re going to use one specific table design strategy: “one table per anchor”. It is one of the most common approaches to physical table design. There are several more possible strategies, we’re going to discuss them in a book. We’re going to revisit the tables from the previous section, and fill in our choices:
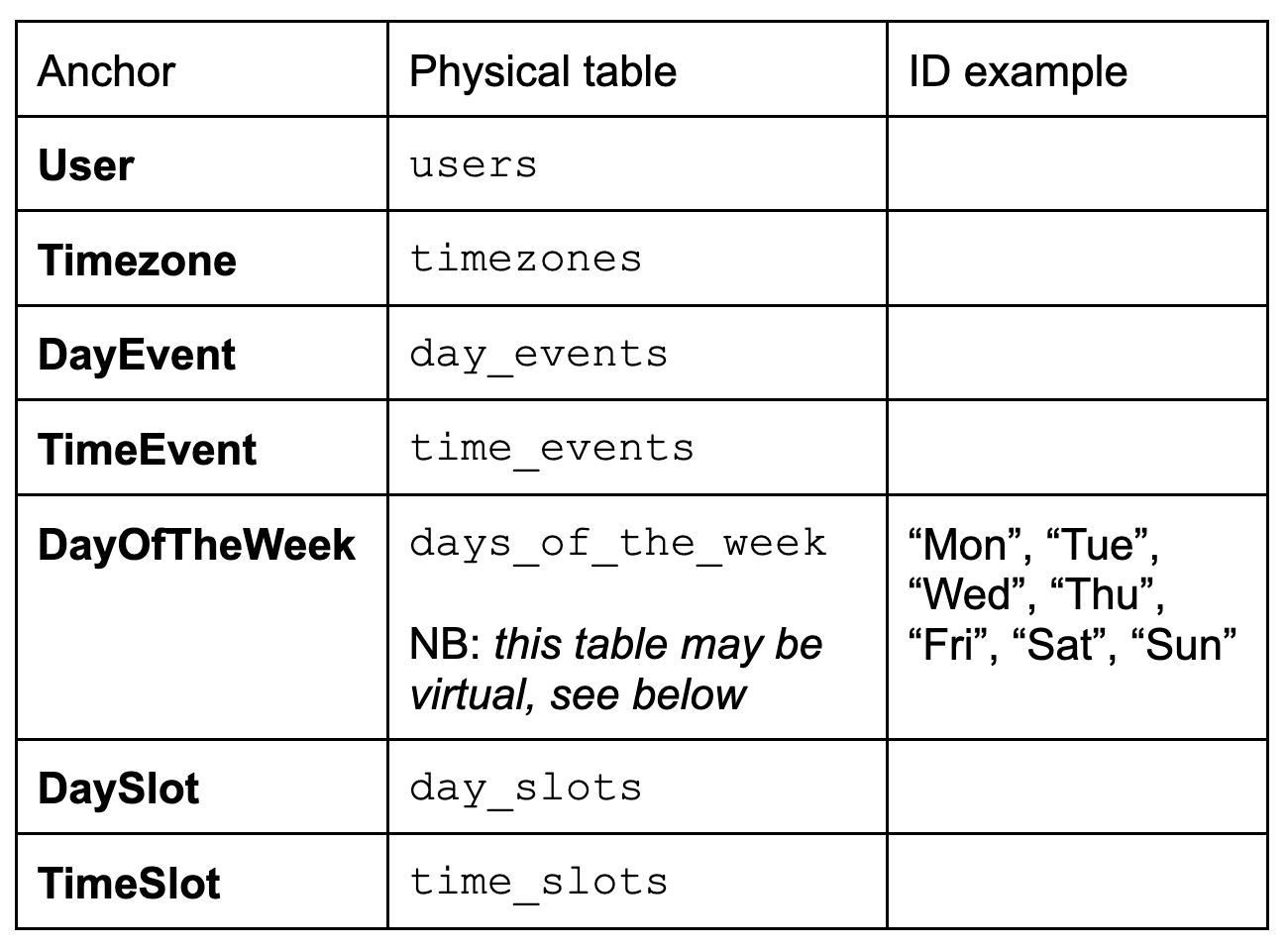
Anchors: choose names for tablesHere we just choose a straightforward plural name for each table.
Some companies or applications enforce different naming conventions (singular, camel case, etc.). In that case, you would just use the names that comply with the convention. Attributes: choose the column name and physical typeFor the physical column name, we choose some sensible name. For example:
And so on. Due to the way relational databases work, you have to choose a very short name. In many cases this name by itself is not enough to fully explain the meaning of the data. That’s one of the reasons why we begin with the logical schema, and use long-ish human-readable questions to define the semantics of the attributes. For the physical type, we choose a sensible type without much discussion. This topic is discussed extensively in the book. There is also a list of recommended data types for each logical type in the book, and we just use that directly. If you’re working with an existing system, you may be required to choose an alternative physical data type for the column. For example, your database server may support a better suited data type; or there could be some engineering guidelines that make you choose a different data type. We’re going to discuss this in the book. However, full discussion of all physical design concerns is well outside of the scope of any book. This is the stuff that you spend your career on learning.
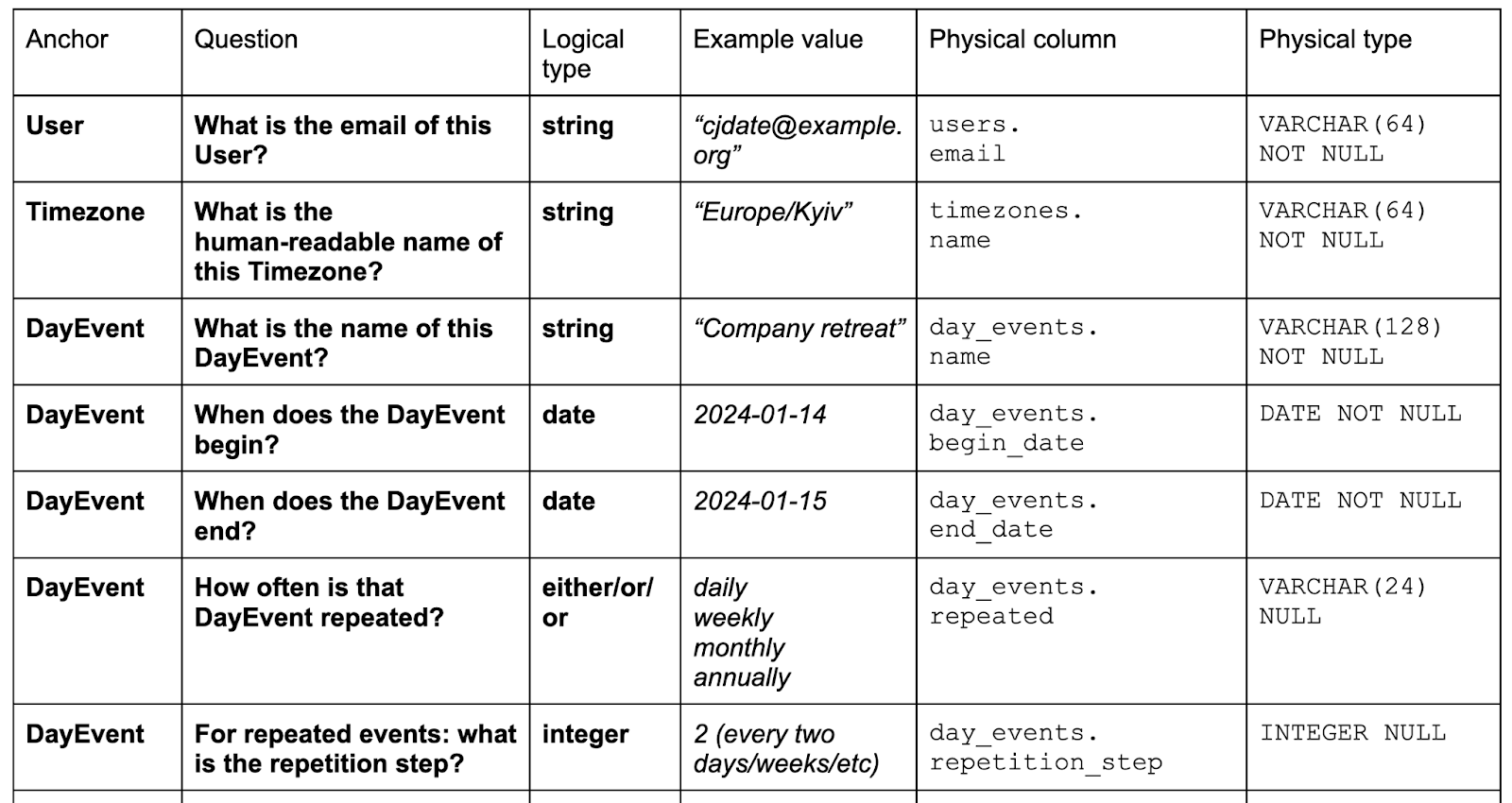
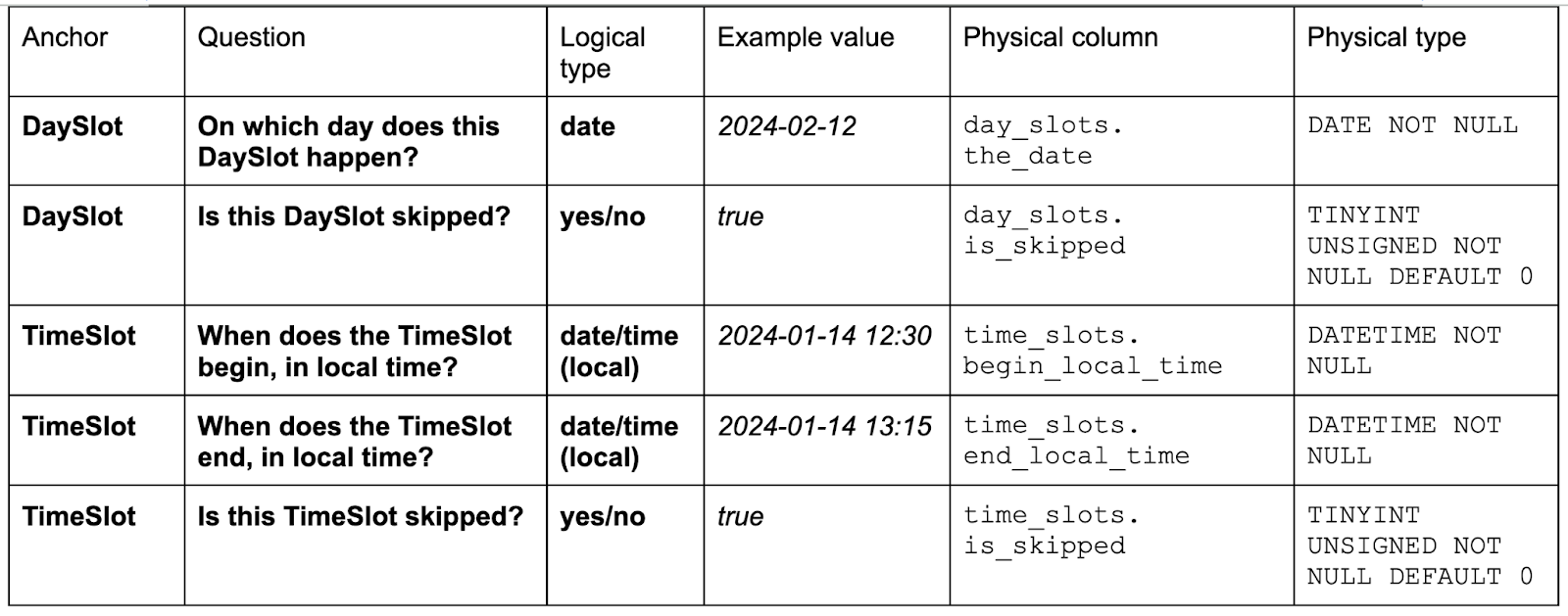
For this problem, we used around half of logical attribute types:
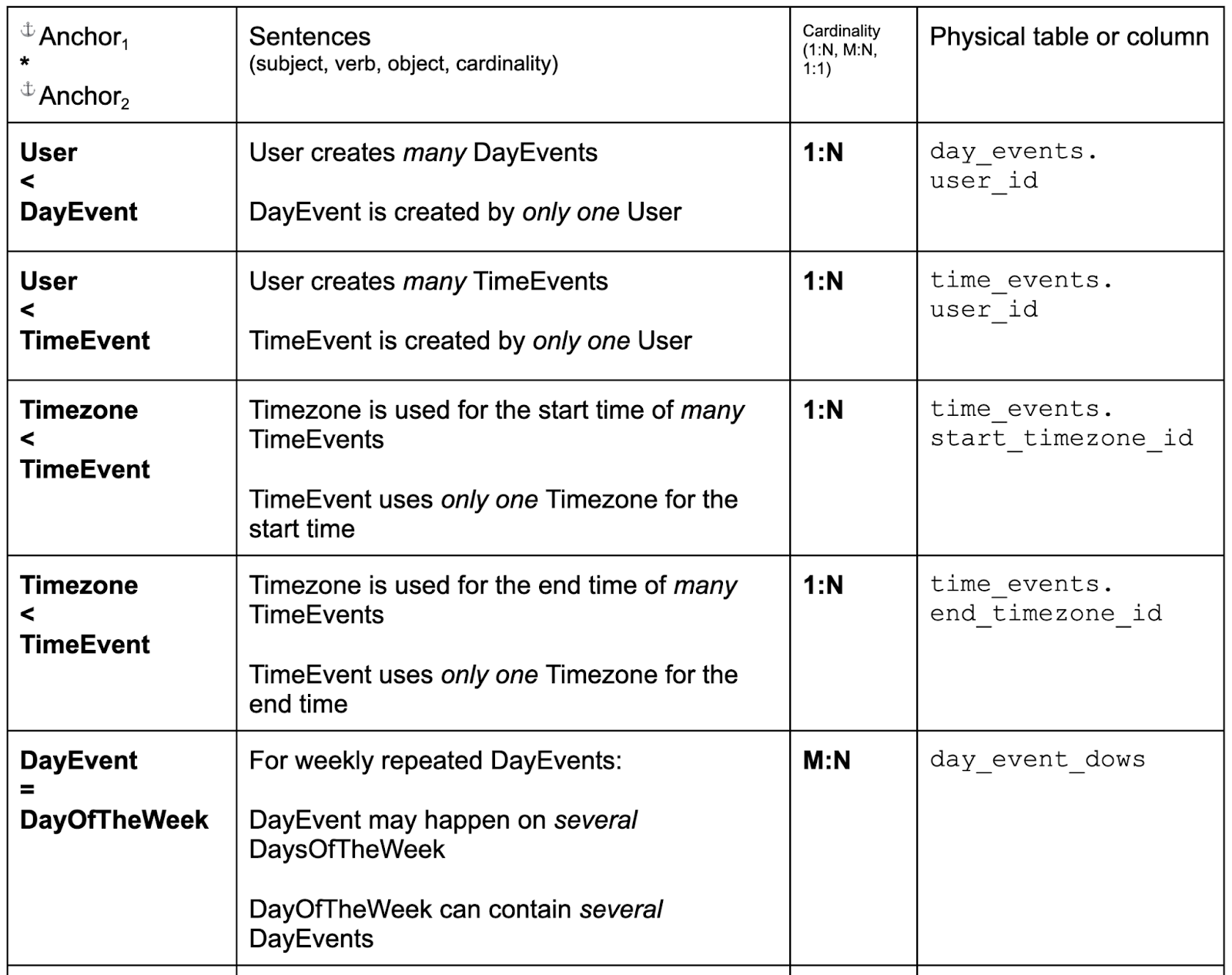
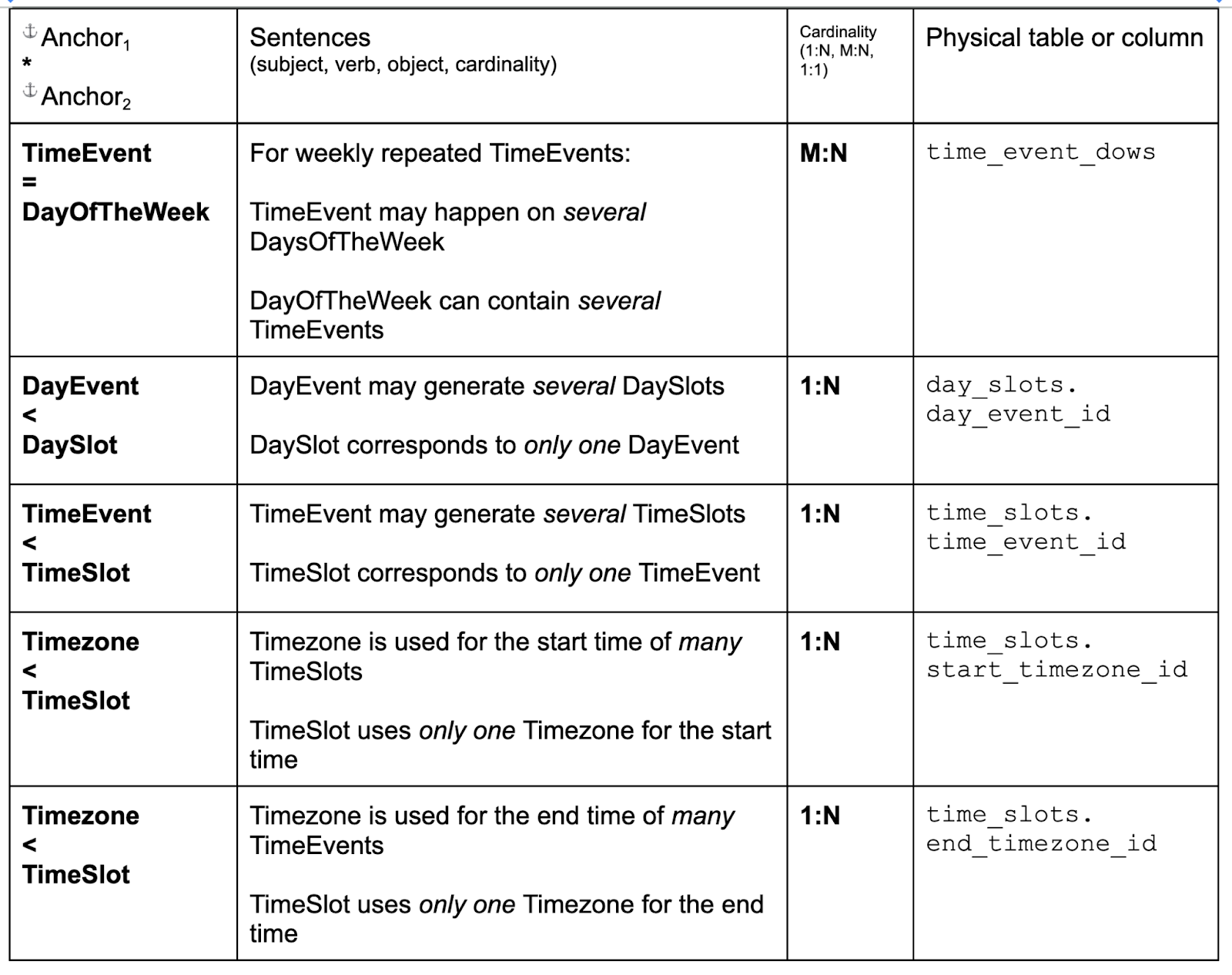
You can see that the physical definitions of attributes of the same logical type are almost the same. The only differences are: a) maximum length of strings; and b) NULL vs NOT NULL. We choose “NOT NULL” for attributes where the value always needs to be there due to business requirements. For example, the name of the event, or the start date of the all-day event. For tangled attributes, we choose nullable physical types (“NULL”). We discuss nullability in the book. 1:N LinksFor 1:N links, we use a column in the N-side anchor table. For example:
Choosing the column name is usually quite easy. The only complication could be when there are two and more different links between the same two anchors. We have that situation with the timezones, and we’ll use two different columns. M:N linksFor M:N links we must use a separate table for each link. Every such table will have identical structure, only the column names would be different. We only need to find a good name for such a table. There is no naming method that works for all, you will have to try some combinations, looking for readability. For links this is especially difficult because it’s not clear which of the two anchors is more important. Same as with attributes, due to the way relational databases work, the name of the table is going to be quite short. In many cases this name by itself is not enough to fully explain the meaning of the data. That’s one of the reasons why we prepare logical schema, and use human-readable sentences to define the semantics of the links. Anyway, here is the full table of links with the names chosen for the tables.
Finally: the tablesAs we mentioned in the previous section, we’re going to have 8 (eight) SQL tables: 6 for anchors and 2 for M:N links. One anchor (DayOfTheWeek) is special, so we don’t create a physical table for that. We use a very common approach to designing physical tables. Other approaches are also possible, but this discussion is outside the scope of this post. So, let’s just write down all the tables, and add all the attributes that we have. This is a very straightforward and even boring process at this point. CREATE TABLE timezones ( CREATE TABLE day_events ( CREATE TABLE time_events ( CREATE TABLE day_slots ( CREATE TABLE time_slots ( CREATE TABLE day_event_dows ( CREATE TABLE time_event_dows ( Is that really it? Mostly, yes. Though we need to talk about indexes and about the attributes that we’ve skipped for brevity. Most experienced database developers would look at the schema above and immediately notice that some “obvious” indexes are missing. For example, day_events.user_id must certainly be indexed. Unfortunately, there is no hard and fast rule on what columns (and combinations of columns) need to be indexed. That depends on how the tables are going to be queried by the application. The best book about database indexes is called “Use The Index, Luke” (https://use-the-index-luke.com/). Go read it. When we were talking about logical schema (especially in the beginning), we skipped some of the attributes, because they were either trivial, or too complicated. For example, we would probably want to add the name of the user, and the column that stores the user’s password hash. Some of the data elements just don’t add anything new to this text, for example the event location, or the list of invited guests. As an exercise, you could go ahead and add the elements that we did not discuss, the ones that you’re interested in. Add a few rows to the catalog tables, fill in the contents of each cell, and then edit the schema definition above to include the missing pieces of data. What’s nextHere is a short summary of the process:
This series illustrated the database design approach explained in the book called “Database Design using Minimal Modeling”, scheduled to be released in Summer 2024. Here is the website of the book: https://databasedesignbook.com/. Leave your email address to receive updates on the book and to get notified about new posts. |


Minimal Modeling
Minimal Modeling: making sense of your database
Previously in the series This is the fifth post in the “Modeling Google Calendar” series. Previously: https://databasedesignbook.com/posts/database-design-for-google-calendar-pt-1 for introduction, problem description and the first part, “Basic all-day events”; https://databasedesignbook.com/posts/database-design-for-google-calendar-pt-2 “Time-based events”, and some discussion of timezones; https://databasedesignbook.com/posts/database-design-for-google-calendar-pt-3 “Repeated all-day...
Introduction This is the fourth post in the “Modeling Google Calendar” series. Previously: https://databasedesignbook.com/posts/database-design-for-google-calendar-pt-1 for introduction, problem description and the first part, “Basic all-day events”; https://databasedesignbook.com/posts/database-design-for-google-calendar-pt-2 “Time-based events”, and some discussion of timezones; https://databasedesignbook.com/posts/database-design-for-google-calendar-pt-3 Repeated all-day events; This...

Introduction This is the third post in the “Modeling Google Calendar” series. Previously: https://databasedesignbook.com/posts/database-design-for-google-calendar-pt-1 for introduction, problem description and the first part, “Basic all-day events”; https://databasedesignbook.com/posts/database-design-for-google-calendar-pt-2 “Time-based events”, and some discussion of timezones; This series illustrates the database design approach explained in the book called “Database Design using Minimal...